

自 Cloudflare 成立之初,我们就一直依靠 ML 和 AI 来提供 Web 应用程序防火墙 (WAF) 等核心服务。在这个过程中,我们学到了很多关于大规模运行 AI 部署的经验,以及所有必要的工具和流程。我们最近推出了 Workers AI,帮助提取出许多推理方法,让开发人员只需几行代码就能轻松利用强大的模型。在本篇文章中,我们将探讨我们在 ML 等式的另一面——训练方面学到的一些经验。
Cloudflare 拥有丰富的模型训练经验,并利用它们来改进我们的产品。不断发展的 ML 模型推动了 WAF Attack Score,有助于保护我们的客户免受恶意有效负载的侵害。另一个不断发展的模型为机器人管理产品提供支持,以捕获和防止机器人对我们客户的攻击。数据科学增强了我们的客户支持。我们构建机器学习来识别我们全球网络上的威胁。最重要的是,Cloudflare 正在我们的网络中以前所未有的规模提供机器学习。
这些产品以及其他许多产品都将 ML 模型(包括实验、培训和部署)提升到了 Cloudflare 的重要位置。为了帮助我们的团队继续高效创新,我们的 MLOps 团队与 Cloudflare 的数据科学家合作实施了以下最佳实践。
Notebooks
给定用例和数据,许多数据科学家/AI 科学家的第一步是建立一个用于探索数据、特征工程和模型实验的环境。Jupyter Notebooks 是满足这些要求的常用工具。这些环境提供了一个简单的远程 Python 环境,可以在浏览器中运行或连接到本地代码编辑器。为了使 Notebook 具有可扩展性并开放协作,我们在 Kubernetes 上部署了 JupyterHub。借助 JupyterHub,我们可以管理数据科学家团队的资源,并确保他们获得合适的开发环境。每个团队都可以通过预安装库和配置用户环境来定制自己的环境,以满足特定需求,甚至单个项目的需求。
这一 Notebook 空间也在不断发展。开源项目还包括更多的功能,例如:
- nbdev:用于改善 Notebook 使用体验的 Python 软件包
- Kubeflow:用于机器学习的 kubernetes 原生 CNCF 项目
- depoyKF:任何 Kubernetes 集群上的 ML 平台,提供集中配置、就地升级,并支持 Kubeflow、Airflow 和 MLflow 等领先的 ML 和数据工具
GitOps
我们的目标是为数据科学家和 AI 科学家提供一个易于使用的平台,以快速开发和测试机器学习模型。因此,我们在 Cloudflare 的 MLOps 平台上采用 GitOps 作为持续交付策略并进行基础设施管理。GitOps 是一种软件开发方法,它利用分布式版本控制系统 Git 作为定义和管理基础设施、应用配置和部署流程的单一来源。其目的是以声明和可审计的方式,自动化和简化应用与基础设施的部署和管理。GitOps 非常符合自动化和协作的原则,这些原则对机器学习 (ML) 工作流程至关重要。GitOps 利用 Git 资源库作为声明式基础设施和应用代码的真实来源。
数据科学家需要定义基础设施和应用的所需状态。这通常需要大量的定制工作,但有了 ArgoCD 和模型模板,只需一个简单的 pull 请求就能添加新的应用。Helm 图表和 Kustomize 均受支持,可以针对不同的环境和作业进行配置。借助 ArgoCD,声明式 GitOps 将启动持续交付流程。ArgoCD 将持续检查基础设施和应用的所需状态,以确保它们与 Git 存储库同步。
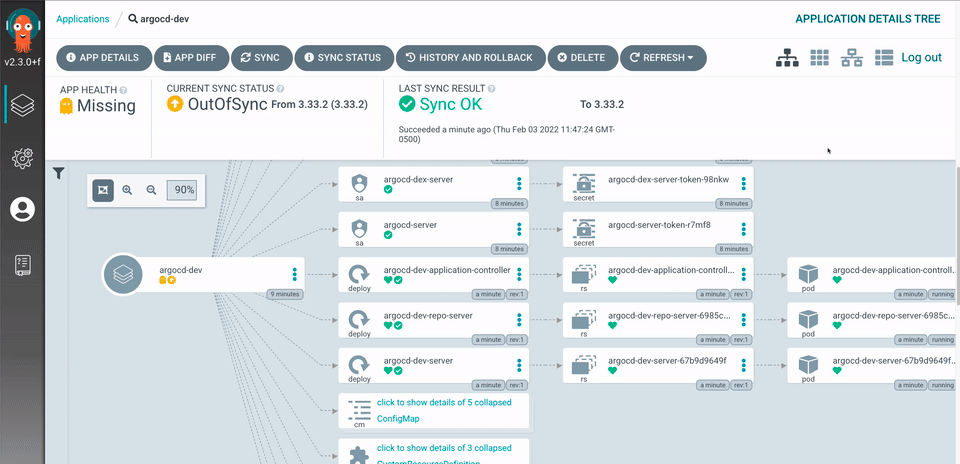
未来,我们计划将我们的平台(包括 Jupyterhub)迁移到 Kubeflow,这是一个基于 Kubernetes 的机器学习工作流程平台,可简化 Notebook 和端到端管道的开发、部署和管理。最好使用新项目 deployKF 进行部署,该项目允许跨 Kubeflow 可用的多个组件以及超出 Kubeflow 的其他组件进行分布式配置管理。
模版
是否使用正确的工具和结构启动项目可能决定项目是成功还是停滞。在 Cloudflare 中,我们策划了一系列模型模板,它们是带有示例模型的生产就绪数据科学存储库。这些模型模板在生产过程中进行部署,以持续确保它们成为未来项目的稳定基础。要启动一个新项目,只需要一个 Makefile 命令即可在用户选择的 git 项目中构建一个新的 CICD 项目。这些模板实用程序包与我们的 Jupyter Notebooks 中使用的模板实用程序包以及与 R2/S3/GCS 存储桶、D1/Postgres/Bigquery/Clickhouse 数据库的连接相同。数据科学家可以使用这些模板充满信心地立即启动新项目。这些模板尚未公开,但我们的团队计划在未来将其开源。
1. 训练模板
我们的模型训练模板为构建任何模型提供了坚实的基础。我们对其进行了配置,可帮助从任何数据源提取、转换和加载数据 (ETL)。该模板包括用于特征工程的 helper 函数、使用模型元数据跟踪实验以及通过有向无环图 (DAG) 选择编排以生产模型管道。每个编排都可以配置为使用 Airflow 或 Argo Workflows。
2. 批量推理模板
批量和微批量推理可以对处理效率产生重大影响。我们的批量推理模型模板用于安排模型以获得一致的结果,并且可以配置为使用 Airflow 或 Argo Workflows。
3. 流式推理模板
该模板使我们的团队可以轻松部署实时推理。该模板使用 FastAPI 针对 Kubernetes 进行了定制(作为微服务),允许我们的团队在容器中使用熟悉的 Python 运行推理。该微服务已经内置了 Swagger 的 REST 交互式文档,并与 terraform 中的 Cloudflare Access 身份验证令牌集成。
4. 可解释性模板
我们的可解释性模型模板会旋转仪表板来阐明模型类型和实验。能够理解时间窗口 F1 分数、特征和数据随时间的漂移等关键值非常重要。Streamlit 和 Bokeh 等工具有助于实现这一目标。
编排
将数据科学组织成一致的管道涉及大量数据和多个模型版本。输入有向无环图 (DAG),这是一种强大的流程图编排范例,它将从数据到模型、模型到推理的步骤编织在一起。运行 DAG 管道有许多独特的方法,但我们发现数据科学团队的偏好是第一位的。每个团队根据自己的用例和经验都有不同的方法。
Apache Airflow——标准 DAG 编写器
Apache Airflow 是基于 DAG(有向无环图)的编排方法的标准。凭借庞大的社区和广泛的插件支持,Airflow 擅长处理不同的工作流。与多个系统集成的灵活性以及用于任务监控的基于 Web 的 UI 使其成为编排复杂任务序列的流行选择。Airflow 可用于运行任何数据或机器学习工作流。
Argo Workflows——Kubernetes 原生的辉煌
Argo Workflows 专为 Kubernetes 构建,采用容器生态系统来编排工作流程。它拥有基于 YAML 的直观工作流定义,并且擅长运行基于微服务的工作流。与 Kubernetes 的集成可实现可扩展性、可靠性和原生容器支持,使其非常适合深深植根于 Kubernetes 生态系统的组织。Argo Workflows 还可用于运行任何数据或机器学习工作流。
Kubeflow 管道——一个工作流平台
Kubeflow Pipelines 是一种更具体的方法,专为编排机器学习工作流而定制。“KFP”旨在满足 ML 领域中数据准备、模型训练和部署的独特需求。作为 Kubeflow 生态系统的集成组件,它简化了 ML 工作流程,重点关注协作、可重用性和版本控制。它与 Kubernetes 的兼容性确保了无缝集成和高效编排。
Temporal——有状态的工作流推动者
Temporal 的立场是强调长期运行、具状态工作流的编排。这个相对较新的领域在管理弹性、事件驱动的应用、保留工作流状态以及实现高效的故障恢复方面表现出色。独特的卖点在于它能够管理复杂、有状态的工作流,提供持久且容错的编排解决方案。
在编排领域,选择最终取决于团队和用例。这些都是开源项目,因此唯一的限制是对不同风格工作的支持,我们发现这是值得投资的。
硬件
实现最佳性能需要了解工作负载和底层用例,以便为团队提供有效的硬件。目标是帮助数据科学家并在支持和利用之间取得平衡。每个工作负载都是不同的,因此针对 GPU 和 CPU 的功能微调每个用例以找到适合该工作的完美工具非常重要。对于核心数据中心工作负载和边缘推理,GPU 提高了速度和效率,这是我们业务的核心。Prometheus 提供可观察性和指标,指标使我们能够跟踪编排以优化性能、最大限度地提高硬件利用率,并在 Kubernetes 原生体验中进行操作。
采用
采用通常是 MLops 之旅中最具挑战性的步骤之一。在开始构建之前,了解不同的团队及其数据科学方法非常重要。在 Cloudflare,这个过程几年前就开始了,当时每个团队都分别启动了自己的机器学习解决方案。随着这些解决方案的发展,我们遇到了在整个公司范围内开展工作以防止不同团队之间的工作相互分离的共同挑战。此外,还有其他团队具有机器学习潜力,但团队内不具备数据科学专业知识。这为 MLops 提供了介入的机会——既可以帮助简化和标准化每个团队所采用的 ML 流程,也可以向数据科学团队引入潜在的新项目,以启动构思和发现过程。
在有能力的情况下,当我们能够帮助启动项目并塑造成功的渠道时,我们就获得了最大的成功。提供共享使用的组件,例如 Notebook、编排、数据版本控制 (DVC)、特征工程 (Feast) 和模型版本控制 (MLflow),让团队能够直接协作。
展望未来
毫无疑问,数据科学正在发展我们的业务和我们客户的业务。我们通过模型改进我们自己的产品,并构建了 AI 基础设施,可以帮助我们保护应用和使用 AI 构建的应用。我们可以利用网络的力量为我们和我们的客户提供 AI。我们与机器学习巨头合作,使数据科学界更容易从数据中提供真正的价值。
行动号召:加入 Cloudflare 社区,将现代软件实践和工具引入数据科学。请关注 Cloudflare 的更多数据科学。帮助我们安全地利用数据来协助构建更好的互联网。