


Starting today, Cloudflare’s API Gateway can protect GraphQL APIs against malicious requests that may cause a denial of service to the origin. In particular, API Gateway will now protect against two of the most common GraphQL abuse vectors: deeply nested queries and queries that request more information than they should.
Typical RESTful HTTP APIs contain tens or hundreds of endpoints. GraphQL APIs differ by typically only providing a single endpoint for clients to communicate with and offering highly flexible queries that can return variable amounts of data. While GraphQL’s power and usefulness rests on the flexibility to query an API about only the specific data you need, that same flexibility adds an increased risk of abuse. Abusive requests to a single GraphQL API can place disproportional load on the origin, abuse the N+1 problem, or exploit a recursive relationship between data dimensions. In order to add GraphQL security features to API Gateway, we needed to obtain visibility inside the requests so that we could apply different security settings based on request parameters. To achieve that visibility, we built our own GraphQL query parser. Read on to learn about how we built the parser and the security features it enabled.
The power of GraphQL
Unlike a REST API, where the API’s users are limited to what data they can query and change on a per-endpoint basis, a GraphQL API offers users the ability to query and change any data they wish with an open-ended, yet structured request to a single endpoint. This open-endedness makes GraphQL APIs very powerful. Each user can query for a completely custom set of data and receive their custom response in a single HTTP request. Here are two example queries and their responses. These requests are typically sent via HTTP POST methods to an endpoint at /graphql.
# A query asking for multiple nested subfields of the "hero" object. This query has a depth level of 2.
{
hero {
name
friends {
name
}
}
}
# The corresponding response.
{
"data": {
"hero": {
"name": "R2-D2",
"friends": [
{
"name": "Luke Skywalker"
},
{
"name": "Han Solo"
},
{
"name": "Leia Organa"
}
]
}
}
}
# A query asking for just one subfield on the same "hero" object. This query has a depth level of 1.
{
hero {
name
}
}
# The corresponding response.
{
"data": {
"hero": {
"name": "R2-D2"
}
}
}
These custom queries give GraphQL endpoints more flexibility than conventional REST endpoints. But this flexibility also means GraphQL APIs can be subject to very different load or security risks based on the requests that they are receiving. For example, an attacker can request the exact same, valid data as a benevolent user would, but exploit the data’s self-referencing structure and ask that an origin return hundreds of thousands of rows replicated over and over again. Let’s consider an example, in which we operate a petitioning platform where our data model contains petitions and signers objects. With GraphQL, an attacker can, in a single request, query for a single petition, then for all people who signed that petition, then for all petitions each of those people have signed, then for all people that signed any of those petitions, then for all petitions that… you see where this is going!
query {
petition(ID: 123) {
signers {
nodes {
petitions {
nodes {
signers {
nodes {
petitions {
nodes {
...
}
}
}
}
}
}
}
}
}
}
A rate limit won’t protect against such an attack because the entire query fits into a single request.
So how can we secure GraphQL APIs? There is little agreement in the industry around what makes a GraphQL endpoint secure. For some, this means rejecting invalid queries. Normally, an invalid query refers to a query that would fail to compile by a GraphQL server and not cause any substantial load on the origin, but would still add noise and error logs and reduce operational visibility. For others, this means creating complexity-based rate limits or perhaps flagging broken object-level authorization. Still others want deeper visibility into query behavior and an ability to validate queries against a predefined schema.
When creating new features in API Gateway, we often start by providing deeper visibility for customers into their traffic behavior related to the feature in question. This way we create value from the large amount of data we see in the Cloudflare network, and can have conversations with customers where we ask: “Now that you have these data insights, what actions would you like to take with them?”. This process puts us in a good position to build a second, more actionable iteration of the feature.
We decided to follow the same process with GraphQL protection, with parsing GraphQL requests and gathering data as our first goal.
Parsing GraphQL quickly
As a starting point, we wanted to collect request query size and depth attributes. These attributes offer a surprising amount of insight into the query – if the query is requesting a single field at depth level 15, is it really innocuous or is it exploiting some recursive data relationship? if the query is asking for hundreds of fields at depth level 3, why wouldn’t it just ask for the entire object at level 2 instead?
To do this, we needed to parse queries without adding latency to incoming requests. We evaluated multiple open source GraphQL parsers and quickly realized that their performance would put us at the risk of adding hundreds of microseconds of latency to the request duration. Our goal was to have a p95 parsing time of under 50 microseconds. Additionally, the infrastructure we were planning to use to ship this functionality has a strict no-heap-allocation policy – this means that any memory allocated by a parser to process a request has to be amortized by being reused when parsing any subsequent requests. Parsing GraphQL in a no-allocation manner is not a fundamental technical requirement for us over the long-term, but it was a necessity if we wanted to build something quickly with confidence that the proof of concept will meet our performance expectations.
Meeting the latency and memory allocation constraints meant that we had to write a parser of our own. Building an entire abstract syntax tree of unpredictable structure requires allocating memory on the heap, and that’s what made conventional parsers unfit for our requirements. What if instead of building a tree, we processed the query in a streaming fashion, token by token? We realized that if we were to write our own GraphQL lexer that produces a list of GraphQL tokens (“comment”, “string”, “variable name”, “opening parenthesis”, etc.), we could use a number of heuristics to infer the query depth and size without actually building a tree or fully validating the query. Using this approach meant that we could deliver the new feature fast, both in engineering time and wall clock time – and, most importantly, visualize data insights for our customers.
To start, we needed to prepare GraphQL queries for parsing. Most of the time, GraphQL queries are delivered as HTTP POST requests with application/json or application/graphql Content-Type. Requests with application/graphql content type are easy to work with – they contain the raw query you can just parse. However, JSON-encoded queries present a challenge since JSON objects contain escaped characters – normally, any deserialization library will allocate new memory into which the raw string is copied with escape sequences removed, but we committed to allocating no memory, remember? So to parse GraphQL queries encoded in JSON fields, we used serde RawValue to locate the JSON field in which the escaped query was placed and then iterated over the constituent bytes one-by-one, feeding them into our tokenizer and removing escape sequences on the fly.
Once we had our query input ready, we built a simple Rust program that converts raw GraphQL input into a list of lexical tokens according to the GraphQL grammar. Tokenization is the first step in any parser – our insight was that this step was all we needed for what we wanted to achieve in the MVP.
mutation CreateMessage($input: MessageInput) {
createMessage(input: $input) {
id
}
}
For example, the mutation operation above gets converted into the following list of tokens:
name
name
punctuator (
punctuator $
name
punctuator :
name
punctuator )
punctuator {
name
punctuator (
name
punctuator :
punctuator $
name
punctuator )
punctuator {
name
punctuator }
punctuator }
With this list of tokens available to us, we built our validation engine and added the ability to calculate query depth and size. Again, everything is done one-the-fly in a single pass. A limitation of this approach is that we can’t parse 100% of the requests – there are some syntactic features of GraphQL that we have to fail open on; however, a major advantage of this approach is its performance – in our initial trial run against a stream of 10s of thousands of requests per second, we achieved a p95 parsing time of 25 microseconds. This is a good starting point to collect some data and to prototype our first GraphQL security features.
Getting started
Today, any API Gateway customer can use the Cloudflare GraphQL API to retrieve information about depth and size of GraphQL queries we see for them on the edge.
As an example, we’ve run the analysis below visualizing over 400,000 data points for query sizes and depths for a production domain utilizing API Gateway.
First let’s look at query sizes in our sample:
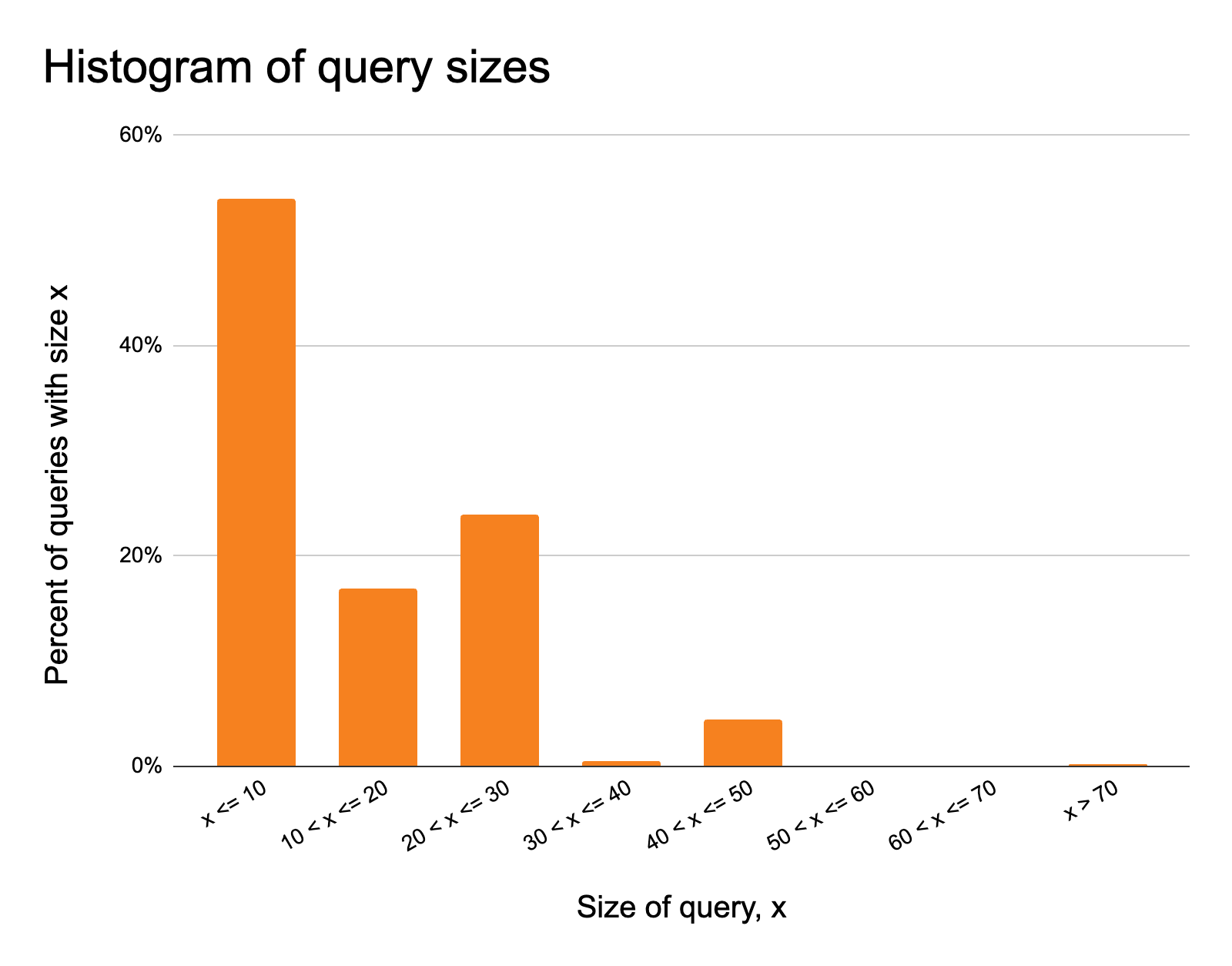
It looks like queries almost never request more than 60 fields. Let’s also look at query depths:
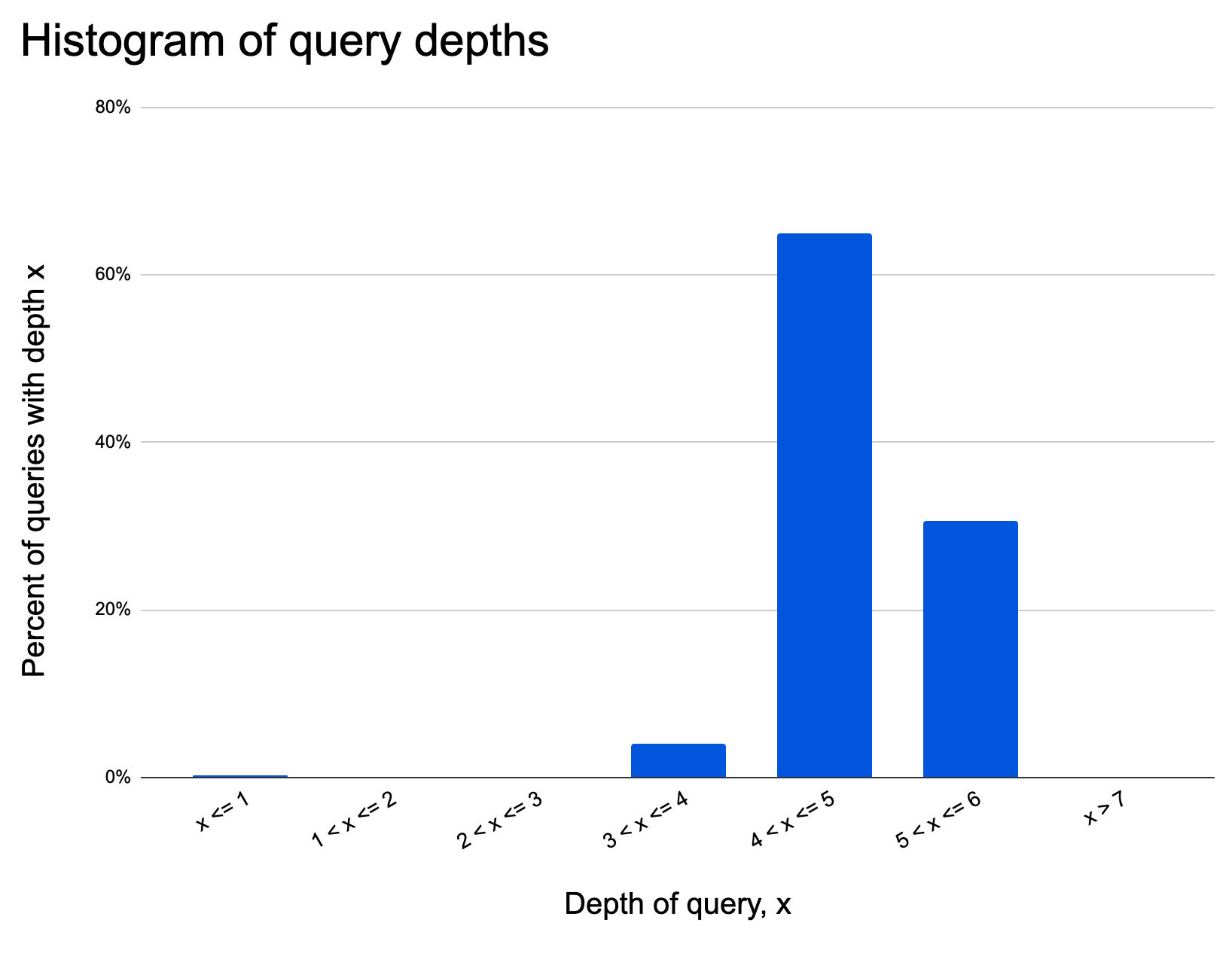
It looks like queries are never more than seven levels deep.
These two insights can be converted into security rules: we added three new Wirefilter fields that API Gateway customers can use to protect their GraphQL endpoints:
1. cf.api_gateway.graphql.query_size
2. cf.api_gateway.graphql.query_depth
3. cf.api_gateway.graphql.parsed_successfully
For now, we recommend the use of cf.api_gateway.graphql.parsed_successfully in all rules. Rules created with the use of this field will be backwards compatible with future GraphQL protection releases.
If a customer feels that there is nothing out of the ordinary with the traffic sample and that it represents a meaningful amount of normal usage, they can manually create and deploy the following custom rule to log all queries that were parsed by Cloudflare and that look like outliers:
cf.api_gateway.graphql.parsed_successfully and
(cf.api_gateway.graphql.query_depth > 7 or
cf.api_gateway.graphql.query_size > 60)
Learn more and run your own analysis with our documentation.
What’s next?
We are already receiving feedback from our first customers and are planning out the next iteration of this feature. These are the features we will build next:
- Integrating GraphQL security with complexity-based rate limiting such that we automatically calculate query cost and let customers rate limit eyeballs based on the total query execution cost the eyeballs use during their entire session.
- Allowing customers to configure specifically which endpoints GraphQL security features run on.
- Creating data insights on the relationship between query complexity and the time it takes the customer origin to respond to the query.
- Creating automatic GraphQL threshold recommendations based on historical trends.
If you’re an Enterprise customer that hasn't purchased API Gateway and you’re interested in protecting your GraphQL APIs today, you can get started by enabling the API Gateway trial inside the Cloudflare Dashboard or by contacting your account manager. Check out our documentation on the feature to get started once you have access.