


Nous sommes heureux d'annoncer aujourd'hui l'ajout dans Workers AI du grand modèle de langage Mistral-7B-v0.1-instruct. Il s'agit d'un modèle à 7,3 milliards de paramètres qui compte un grand nombre d'avantages uniques. Avec l'aide des fondateurs de Mistral AI, nous allons présenter certains points forts du modèle Mistral 7B. Nous profiterons également de l'occasion pour étudier en détail le concept d'attention et ses variantes telles que l'attention multi-requête (MQA pour multi-query attention) et l'attention par requête groupée (GQA pour grouped-query attention).
Mistral 7B tl;dr:
Mistral 7B est un modèle à 7,3 milliards de paramètres qui affiche des résultats impressionnants lors des évaluations des performances. Le modèle :
- obtient de meilleurs résultats que Llama 2 13B dans toutes les évaluations
- obtient de meilleurs résultats que Llama 1 34B dans toutes les évaluations,
- parvient à des performances presque identiques à celles de CodeLlama 7B en ce qui concerne le code, tout en restant performant dans les tâches liées à l'anglais et
- la version plus avancée du chat que nous avons déployée donne de meilleurs résultats que celui de Llama 2 13B dans les évaluations fournies par Mistral.
Voici un exemple d'utilisation de la diffusion en continu avec l'API REST :
curl -X POST \
“https://api.cloudflare.com/client/v4/accounts/{account-id}/ai/run/@cf/mistral/mistral-7b-instruct-v0.1” \
-H “Authorization: Bearer {api-token}” \
-H “Content-Type:application/json” \
-d '{ “prompt”: “What is grouped query attention”, “stream”: true }'
API Response: { response: “Grouped query attention is a technique used in natural language processing (NLP) and machine learning to improve the performance of models…” }
Et voici un exemple avec un script Workers :
import { Ai } from '@cloudflare/ai';
export default {
async fetch(request, env) {
const ai = new Ai(env.AI);
const stream = await ai.run('@cf/mistral/mistral-7b-instruct-v0.1', {
prompt: 'What is grouped query attention',
stream: true
});
return Response.json(stream, { headers: { “content-type”: “text/event-stream” } });
}
}
Mistral met à profit l'attention par requête groupée pour accélérer l'inférence. Cette technique récemment développée améliore la vitesse d'inférence sans compromettre la qualité du résultat. Pour des modèles à 7 milliards de paramètres, nous pouvons générer près de quatre fois plus de jetons par seconde avec Mistral qu'avec Llama, grâce à l'attention par requête groupée.
À ce stade, vous n'avez pas besoin de plus d'informations pour commencer à utiliser Mistral-7B, vous pouvez le tester dès aujourd'hui ai.cloudflare.com. Pour en savoir plus sur l'attention en général et l'attention par requête groupée, poursuivez la lecture !
Avant toute chose, qu'est-ce que « l'attention » ?
Le mécanisme de base de l'attention, plus précisément « Scaled Dot-Product Attention » (Attention à produit scalaire pondéré) tel qu'il est présenté dans l'article qui fut déterminant Attention Is All You Need, est relativement simple :
Nous appelons notre attention particulière « Scale Dot-Product Attention » (Attention à produit scalaire pondéré). Les données d'entrée sont constituées d'une requête et des clés de dimension d_k, ainsi que des valeurs de dimension d_v. Nous calculons les produits scalaires de la requête avec toutes les clés, avant de les diviser chacun par sqrt(d_k) et d'appliquer une fonction softmax pour obtenir la pondération des valeurs.
Plus concrètement, voici à quoi cela ressemble :
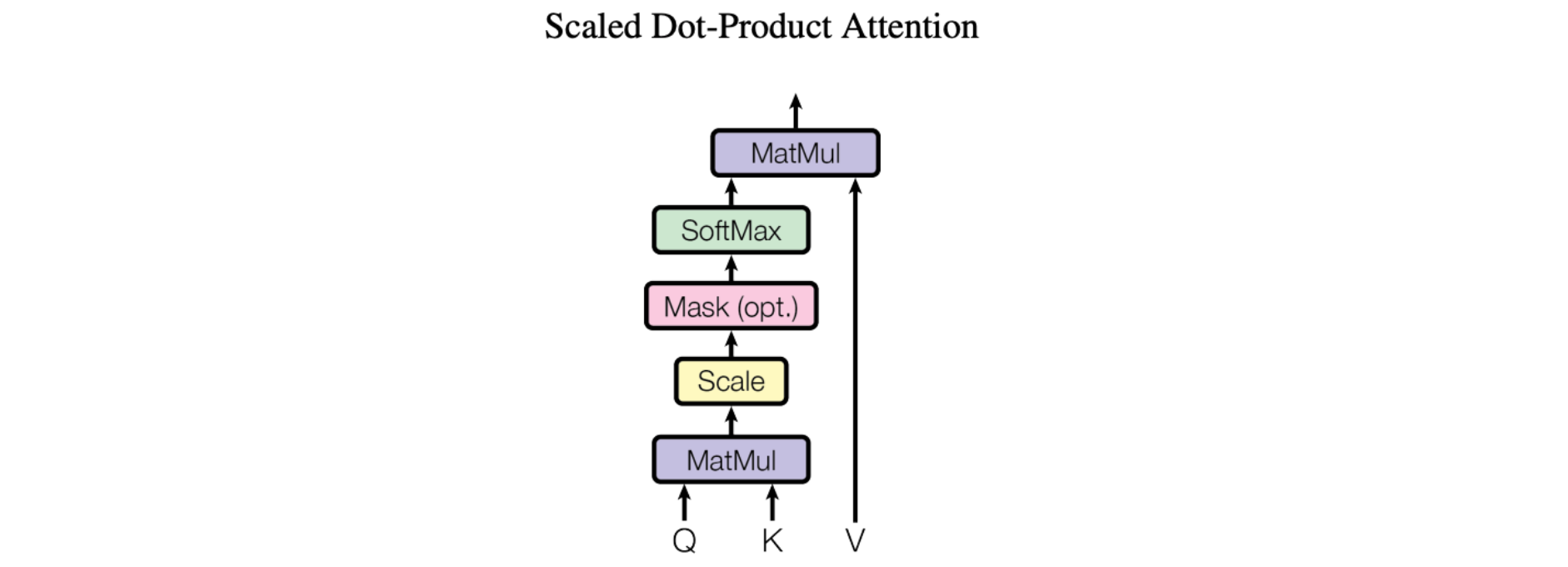
En termes plus simples, ce type d'attention permet aux modèles de se concentrer sur des éléments essentiels de l'entrée. Imaginez-vous en train de lire une phrase et d'essayer de la comprendre. Avec l'attention à produit scalaire pondéré, vous lisez en priorité certains mots en fonction de leur pertinence. Pour ce faire, l'attention calcule la similarité entre chaque mot (K) de la phrase et une requête (Q). Ensuite, les scores de similarités sont divisés par la racine carrée de la dimension de la requête. Cette mise à l'échelle permet d'éviter les valeurs très petites ou très grandes. Enfin, ces scores de similarité ainsi divisés nous permettent d'établir l'attention ou l'importance à accorder à chaque mot. Grâce à ce mécanisme d'attention, les modèles peuvent identifier les informations qui sont cruciales (V) et améliorer leurs capacités de compréhension et de traduction.
C'est simple non ? Pour passer de ce simple mécanisme à une intelligence artificielle capable d'écrire un épisode de Seinfeld dans lequel Jerry apprend l'algorithme du tri à bulles, il nous faut le rendre plus complexe. (En réalité, dans tout ce que nous avons présenté, il n'existe pas encore de paramètres appris ; des valeurs constantes apprises au cours de l'entraînement du modèle et qui permettent de personnaliser le résultat du bloc d'attention !)
Les blocs d'attention dans le style de ceux de l'article Attention is All You Need ajoutent essentiellement trois types de complexité :
Paramètres appris
Les paramètres appris correspondent aux valeurs ou aux poids qui sont ajustés pendant le processus d'entraînement d'un modèle dans le but d'en améliorer les performances. Ces paramètres servent à contrôler le flux d'information ou d'attention au sein d'un modèle, afin de le concentrer sur les éléments les plus pertinents des données d'entrées. En d'autres termes, les paramètres appris sont comparables à des boutons sur une machine, qu'il est possible de régler pour en optimiser le fonctionnement.
Empilement vertical - blocs d'attention en couches
L'empilement en couches vertical est une façon d'empiler de multiples mécanismes d'attention les uns au-dessus des autres, chaque couche reprenant le résultat de la couche précédente. Le modèle est ainsi en mesure de centrer ses efforts sur différentes parties des données entrées à différents niveaux d'abstraction, ce qui améliore les performances pour certaines tâches.
L'empilement parallèle, également appelé attention multi-tête
La figure illustrant l'article présente le modèle d'attention multi-tête. De multiples opérations d'attention sont exécutées en parallèle, l'entrée Q-K-V de chacune étant générée par une projection linéaire unique des mêmes données d'entrée (définie par un ensemble unique de paramètres appris). Les blocs d'attention parallèle sont appelés « têtes d'attention ». Les résultats pondérés de toutes les têtes d'attention sont réunis dans un vecteur unique et subissent une autre transformation linéaire paramétrée avant de produire le résultat final.
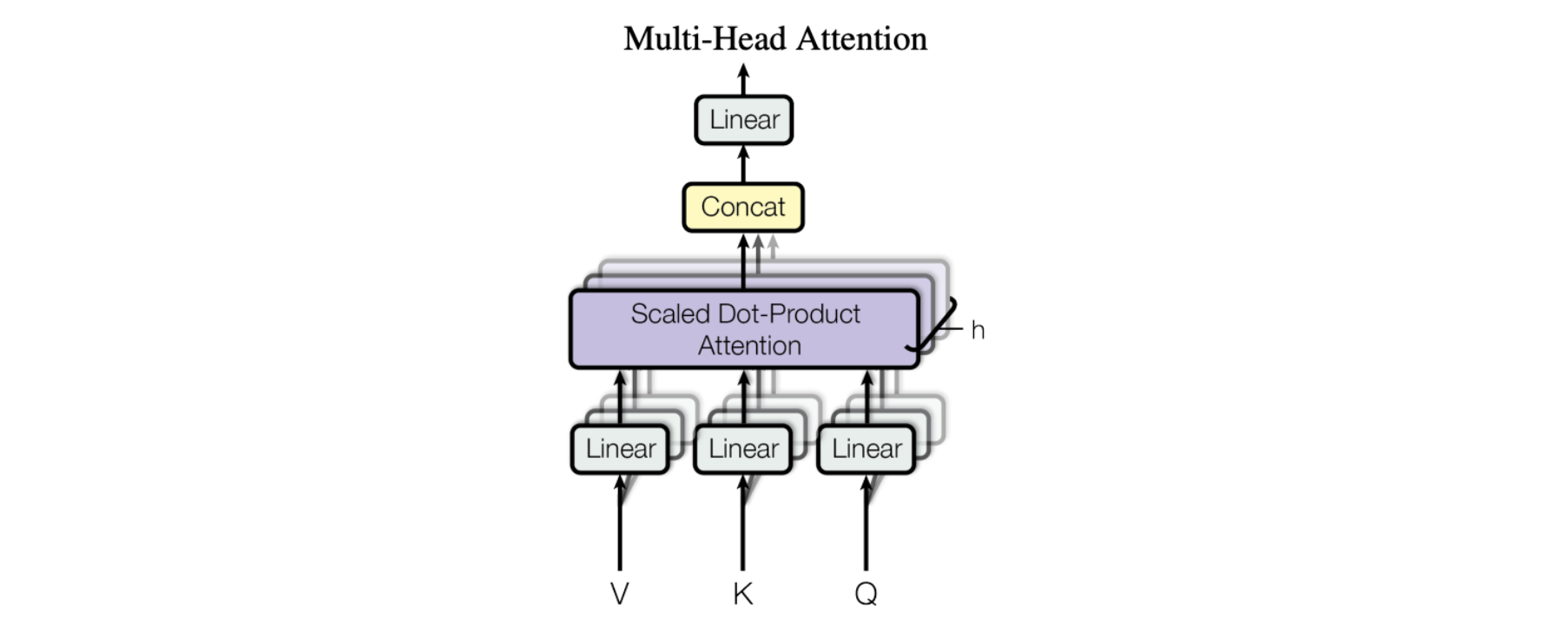
Avec ce mécanisme le modèle se concentre sur différents éléments des données d'entrée en même temps. Imaginez que vous essayez de comprendre une information complexe telle qu'une phrase ou un paragraphe. Pour la comprendre, vous devez examiner plusieurs éléments différents en même temps. Vous devez par exemple faire attention au sujet de la phrase, au verbe et à l'objet, le tout simultanément pour comprendre le sens de la phrase. L'attention multi-tête fonctionne de la même manière. Elle permet tau modèle de se concentrer sur différents éléments des données d'entrée en même temps, à l'aide des multiples « têtes » d'attention. Chaque tête d'attention centre ses efforts sur différents éléments des données d'entrée et le résultat de toutes les têtes est combiné pour produire le résultat final du modèle.
Types d'attention
Trois arrangements courants pour les blocs d'attention sont utilisés par les grands modèles de langage développés au cours des dernières années, l'attention multi-tête (MHA), l'attention par requête groupée (GQA) et l'attention multi-requête (MQA). Ils diffèrent dans le nombre de vecteurs K et V relatif au nombre de vecteurs de requêtes. L'attention multi-tête utilise le même nombre de vecteurs K et V que de vecteurs Q, indiqué par la lettre « N » dans le tableau ci-dessous. L'attention multi-requête utilise un vecteur K et V unique. L'attention par requête groupée, le type utilisé dans le modèle Mistral 7B, divise les vecteurs Q en parts égales contenant « G » vecteurs chacunes, elle utilise ensuit un vecteur K et V unique pour chaque groupe, pour un total de N divisé par G ensembles de vecteurs K et V. Le tableau 1 ci-dessous présente un récapitulatif des différences, et nous allons expliquer ensuite ce qu'elles impliquent.
Récapitulatif des styles d'attention
Ce diagramme illustre les différences entre les trois styles :
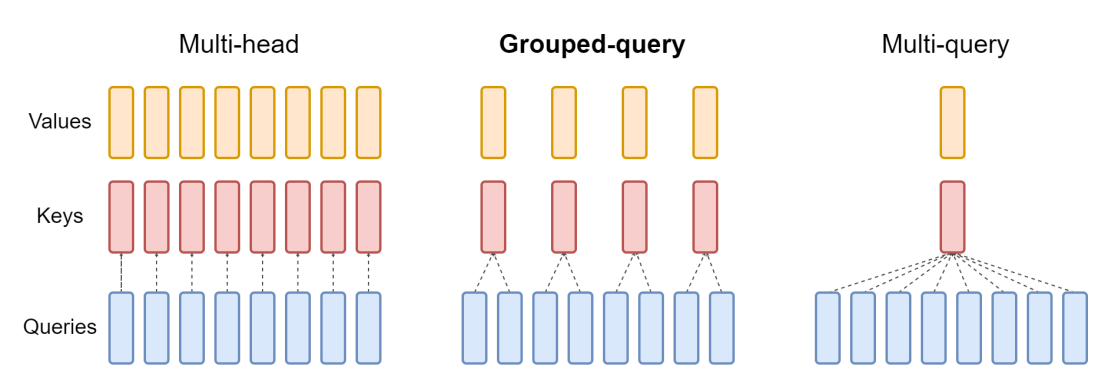
Attention multi-requête
L'attention multi-requête a été présentée en 2019 dans la publication de Google : Fast Transformer Decoding: One Write-Head is All You Need. L'idée est qu'au lieu de créer des entrées K et V séparées pour chaque vecteur Q dans le mécanisme d'attention, ce qui correspond à l'attention multi-tête mentionnée précédemment, un seul vecteur K et V est utilisé pour l'ensemble des vecteurs Q. Comme le nom le suggère, de multiples requêtes sont combinées dans un mécanisme d'attention unique. Dans la publication, l'évaluation comparative dudit mécanisme se faisait sur une tâche de traduction et ses performances étaient équivalentes à celles de l'attention multi-tête.
À l'origine, l'idée était de réduire la quantité totale de mémoire à laquelle il était nécessaire d'accéder pendant l'exécution de l'inférence pour le modèle. Depuis, des modèles généralisés sont apparus, avec des paramètres toujours plus nombreux, en conséquence, la mémoire processeur nécessaire est souvent le goulot d'étranglement et c'est ce qui fait la force de l'attention multi-requête. C'est, parmi les trois types d'attention, celle qui exige le moins de mémoire d'accélération. Cependant, à mesure que les modèles gagnaient en volume et en généralité, les performances de l'attention multi-requête ont régressé par rapport à celles de l'attention multi-tête.
Attention par requête groupée
La plus récente des trois (celle utilisée par Mistral) est l'attention par requête groupée, telle qu'elle est décrite dans la publication GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints sortie sur arxiv.org en mai 2023. L'attention par requête groupée combine le meilleur des deux autres versions : la qualité de l'attention multi-tête d'une part et la vitesse et faible consommation de mémoire de l'attention multi-requête d'autre part. Au lieu d'avoir soit un ensemble unique de vecteurs K et V, soit un ensemble pour chaque vecteur Q, un rapport fixe d'un ensemble de vecteurs K et V pour chaque vecteur Q est utilisé, ce qui réduit la consommation de mémoire sans nuire aux performances pour de nombreuses tâches.
Souvent, la sélection d'un modèle pour une tâche de production ne se résume pas à simplement choisir le meilleur modèle disponible car il convient de trouver le bon équilibre entre performances, utilisation de la mémoire, taille des lots et le matériel disponible (ou les coûts de cloud). Il peut être utile de comprendre le fonctionnement de ces trois styles d'attention au moment de prendre une décision, afin de savoir pourquoi il est préférable de choisir un modèle particulier en fonction des circonstances.
Découvrez Mistral — essayez-le dès aujourd'hui
S'agissant d'un des premiers grands modèles de langage à exploiter l'attention par requête groupée et à la combiner avec l'attention à fenêtre coulissante, Mistral semble avoir atteint un idéal : un modèle à faible latence, avec un haut débit et qui obtient un très bon classement dans les évaluations comparatives, même en face de modèles plus importants (13B). Autant dire qu'il est impressionnant pour sa taille et que nous sommes on ne peut plus heureux de le mettre à disposition de tous les développeurs aujourd'hui, dans le cadre de Workers AI.
Consultez nos documents pour développeurs afin de vous lancer, et si vous avez besoin d'aide ou si vous souhaitez nous faire part de vos commentaires ou nous expliquer ce que vous êtes en train de développer, contactez-nous sur Developer Discord !
L'équipe Workers AI se développe et recrute ; consultez les postes vacants sur notre page de recrutement si vous êtes passionné par l'ingénierie de l'intelligence artificielle et que vous souhaitez participer à la création et à l'évolution d'une plateforme d'inférence serverless reposant sur des processeurs graphiques.